想了解更多技术分享请搜索“技术”标签,本人水平有限,内容可能不严谨或存在错误,如有发现错误请在评论区处留言,欢迎批评指正。
低配本地部署无限制千问和混元翻译模型教程
一、前言
1.什么是本地部署大语言模型
本地部署大语言模型,就是把 AI 模型下载到自己的电脑上运行,不依赖网页端、不需要排队,也不用每次都把内容发送到第三方服务器,也可以实现无审回答,保护隐私数据。对于低配电脑来说,最关键的是选择合适的量化模型,本教程已经测试包括 Q4_K_M、IQ2_M 这两种 GGUF 格式模型,再配合 llama.cpp 运行,本人的电脑配置实测能够正常运行。
2. 关于无限制千问和混元翻译模型
本文主要部署两个模型:
- 千问 Qwen:适合写提示词、聊天、角色扮演、文案生成,可搭配酒馆使用
- 混元翻译 Hunyuan-MT:适合多语种互译、长文本翻译、本地翻译接口
所谓“无限制”主要指本地模型由自己运行,不会拒绝你的问题,不依赖在线平台的账号、额度和接口限制。但仍建议合理使用,不要用于违法、侵权或恶意用途。
二、部署过程
1. 电脑配置建议
低配部署不一定需要顶级显卡,但需要注意显存和内存。
推荐配置:
- 显卡:6GB 显存起步,8GB 更舒服
- 内存:16GB 起步,32GB 推荐
- 硬盘:至少预留 50GB 空间
- 系统:Windows 10 / Windows 11
- 显卡驱动:建议更新到较新版本
如果只是写提示词,不追求超长上下文和高并发,8GB 显存已经可以跑不少量化模型。
2. 准备目录
建议统一放到一个目录,方便管理:
D:\AppData\AI
├── llama
├── cuda
├── models
└── 启动Qwen3.6.cmd
其中:
- llama:放 llama.cpp 程序
- cuda:放 CUDA 相关运行库
- models:放 GGUF 模型文件
- 启动Qwen3.6.cmd:一键启动脚本
3. 下载 llama.cpp
官方下载页:Releases · ggml-org/llama.cpp
需要下载 Windows CUDA 版本的 llama.cpp和cuda。
下载后解压到:
D:\AppData\AI\llama 和 D:\AppData\AI\cuda。
确认里面有:
llama-server.exe
这个程序负责把本地模型启动成一个 OpenAI 兼容接口。
4. 下载千问 GGUF 模型
下载地址:https://huggingface.co/HauhauCS/Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive
模型放到:
D:\AppData\AI\models
低配优先推荐:
Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf
如果显存和内存更充足,可以选择:
Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
多模态投影文件,可选:
mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf
简单选择建议:
- 6GB / 8GB 显卡:优先 IQ2_M
- 8GB 显卡 + 32GB 内存:可以试 Q4_K_M
- 只写提示词:IQ2_M 已经够用
- 追求质量:选 Q4_K_M
5. 下载混元翻译模型
下载地址:https://huggingface.co/mradermacher/Hunyuan-MT-7B-i1-GGUF
混元翻译模型同样放到:
D:\AppData\AI\models
例如:
Hunyuan-MT-7B.i1-Q4_K_M.gguf
这个模型比 35B 千问小很多,更适合专门做翻译。
6. 编写一键启动脚本
可以新建:
D:\AppData\AI\启动Qwen3.6.cmd
脚本里做成菜单形式(点我)
@echo off
chcp 65001 >nul
title 本地AI启动器
cd /d "%~dp0llama"
:menu
cls
echo ==========================================
echo 本地AI模型启动器
echo ==========================================
echo.
echo 1. 启动 Qwen Q4_K_M
echo 2. 启动 Qwen IQ2_M
echo 3. 启动 Hunyuan-MT 翻译模型
echo.
echo ==========================================
set /p choice=请输入数字:
if "%choice%"=="1" (
llama-server.exe ^
-m "..\models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf" ^
-ngl 999 ^
-c 8192 ^
-n 4096 ^
--host 127.0.0.1 ^
--port 8080 ^
--chat-template chatml
)
if "%choice%"=="2" (
llama-server.exe ^
-m "..\models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf" ^
-ngl 999 ^
-c 8192 ^
-n 4096 ^
--host 127.0.0.1 ^
--port 8080 ^
--chat-template chatml
)
if "%choice%"=="3" (
llama-server.exe ^
-m "..\models\Hunyuan-MT-7B.i1-Q4_K_M.gguf" ^
-ngl 999 ^
-c 8192 ^
-n 2048 ^
--host 127.0.0.1 ^
--port 8081
)
pause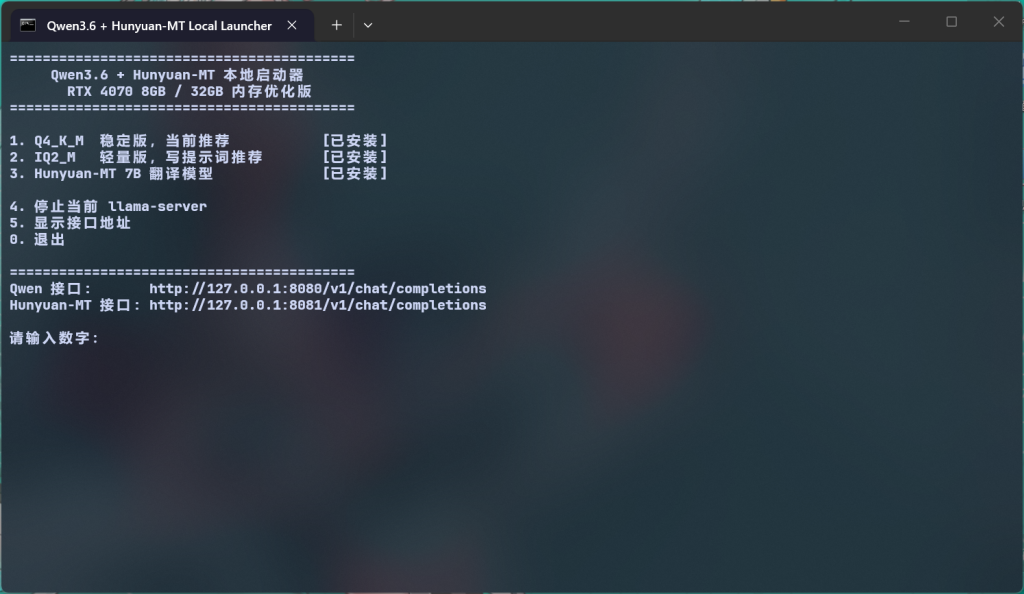
7. 启动模型
双击启动脚本后,根据需要选择:
- 千问模型:访问 http://127.0.0.1:8080
- 混元翻译模型:访问 http://127.0.0.1:8081
如果看到服务启动成功,说明模型已经加载完成。
8. 接入 SillyTavern (酒馆)或其他前端
如果使用 SillyTavern(酒馆)可以这样配置:
API 类型:Chat Completion API 地址:http://127.0.0.1:8080/v1 模型名:qwen-local
官方 Windows 安装文档:
https://docs.sillytavern.app/installation/windows
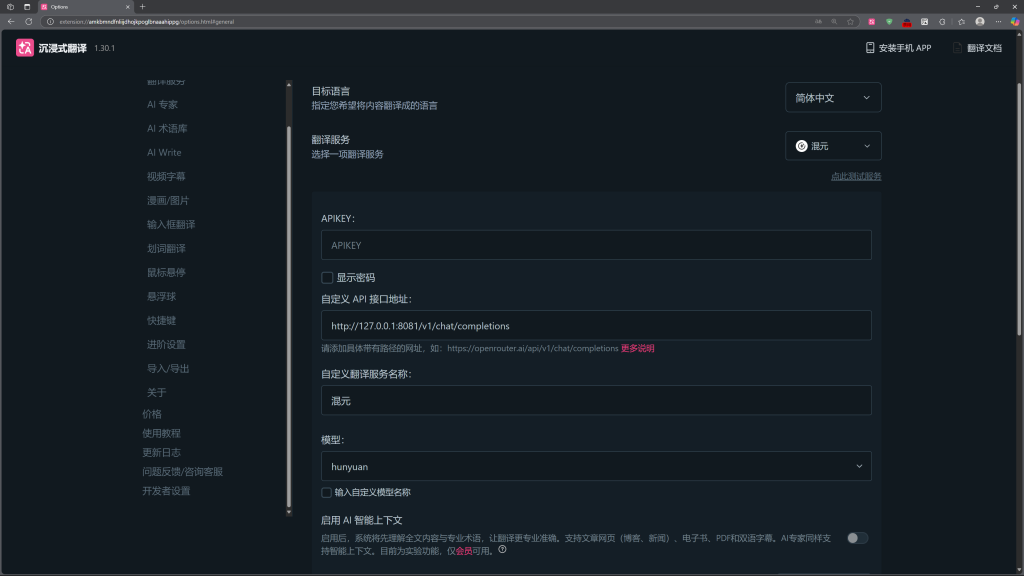
混元翻译可以单独接(沉浸式翻译插件使用示例):
API 地址:http://127.0.0.1:8081/v1 模型名:hunyuan-mt
沉浸式翻译 – 新一代AI翻译软件 | 双语对照网页翻译/PDF翻译/视频字幕翻译/漫画&图片翻译
9. 常见参数解释
-m:模型路径
-ngl:GPU 加速层数,999 表示尽量全部放到显卡
-c:上下文长度
-n:单次最大输出长度
–host:监听地址
–port:端口
–chat-template:聊天模板,千问建议用 chatml
10. 低配优化建议
如果显存不够,可以这样调:
- 把 Q4_K_M 换成 IQ2_M
- 把 -c 8192 降到 4096
- 关闭浏览器、游戏、剪辑软件
- 不要同时运行 ComfyUI 和大语言模型
- 任务管理器里查看显存占用
- 优先用小模型做翻译,大模型做创作
11. 常见问题
启动后很慢怎么办?
第一次加载模型会比较慢,尤其是大模型。只要没有报错,可以等待一会。
显存占满怎么办?
降低上下文长度,或者换更低量化版本。
输出速度差不多正常吗?
正常。很多时候瓶颈不是模型大小,而是显存、内存带宽、上下文长度和 CPU 调度。
超过上下文会怎么样?
模型会遗忘前面的内容,或者服务端截断旧内容。建议长对话定期重新开启。